
Author: Steve Lock
In a nutshell, data observability is a process and a series of tooling and tasks designed to help monitor and validate data quality, and identify problems with data on your analytics platform.
In terms of scope, it can vary greatly from smaller projects to ensuring the data health of large enterprises. For this article, we’ll cover examples of both and how you can understand at a high level how it can be implemented into your organizations.
Benefits of Data Observability
Here’s why you should care:
Data observability gives you better data quality, faster troubleshooting when there are problems, and is critical for compliance in heavily regulated industries.
For smaller organizations, you need to closely monitor the basics, as losing a key data point, such as website conversions, can cause major problems if left undetected.
For larger organizations, focusing on data observability is worthwhile because, at a minimum, it makes your data teams and processes far more efficient. Any investment is likely to deliver a strong return, even if the only immediate benefit is saving your team a significant amount of time.
Key Areas of Data Observability
IBM published a fantastic article on this topic. It includes outlining the 5 pillars of data observability, which is an elegant way to cover the most important points.
- Freshness: How recently has the data been updated
- Distribution: Whether the data values match expectations in terms of ranges
- Volume: Whether the number of rows fall within an acceptable range
- Schema: If the naming or shape of your data changes it will often break processes
- Lineage: If data is processed via multiple systems it can help identify where the problem is coming from
As mentioned, for larger enterprises all of these areas are important. Below is our reproduction of an IBM diagram that shows the relationship between each layer of data.
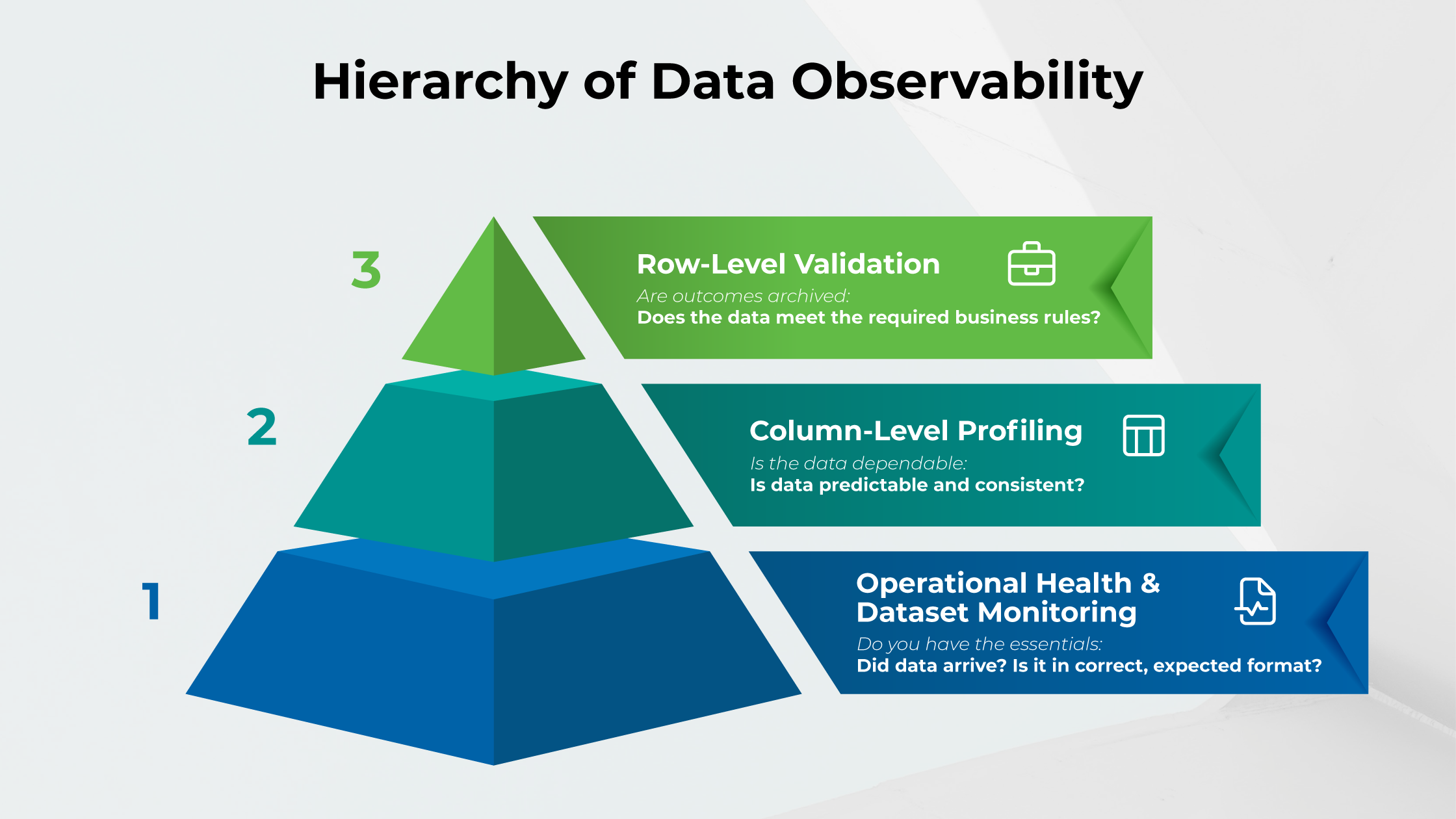
For smaller projects, the basics you should have in place are exception reporting, a data quality dashboard and alerts. It also doesn’t have to be over-engineered or expensive.
With a data visualization tool, you can build data quality dashboards the same way as any other project.
Also depending on the platforms you’re using, you can easily configure alerts. For example, GA4 can supply automated insights without the need for any engineering as you can see below. It even supports machine learning out of the box.

Conclusion
For enterprises, it’s strongly recommended to stand up dedicated projects and resourcing for every dollar invested in data observability. When executed well, it will streamline your data team and make them far more efficient. It will also dramatically speed up resolution time, if and when there are problems.
For smaller projects, there is a great opportunity to shoehorn in profiling data to define ranges in the data that’s expected, exception reporting, data quality dashboards and enabling alerting across all of the systems in your data platform that support them.
PS. Before investing in data observability for your analytics platform, you need the right partner. Don’t sign a contract until you check this out: 4 things to know before hiring a Data Analytics expert.




